Well, we’ve been working with singly-linked lists for two lessons now, so now it’s time to cover doubly-linked lists. Unlike singly-linked lists, doubly-linked lists have nodes with two Node*s. This is what a doubly-linked list node struct looks like on code when its data is an int.
struct DNode
{
int data;
DNode* next;
DNode* prev;
};
As you can see, the doubly-linked list nodes have two pointers, one pointing to the next node on the list and the other pointing to the last node on the list.
The other thing that is different about a doubly-linked list it often includes a second pointer at the end of the list called a tail. The doubly-linked list looks like this:
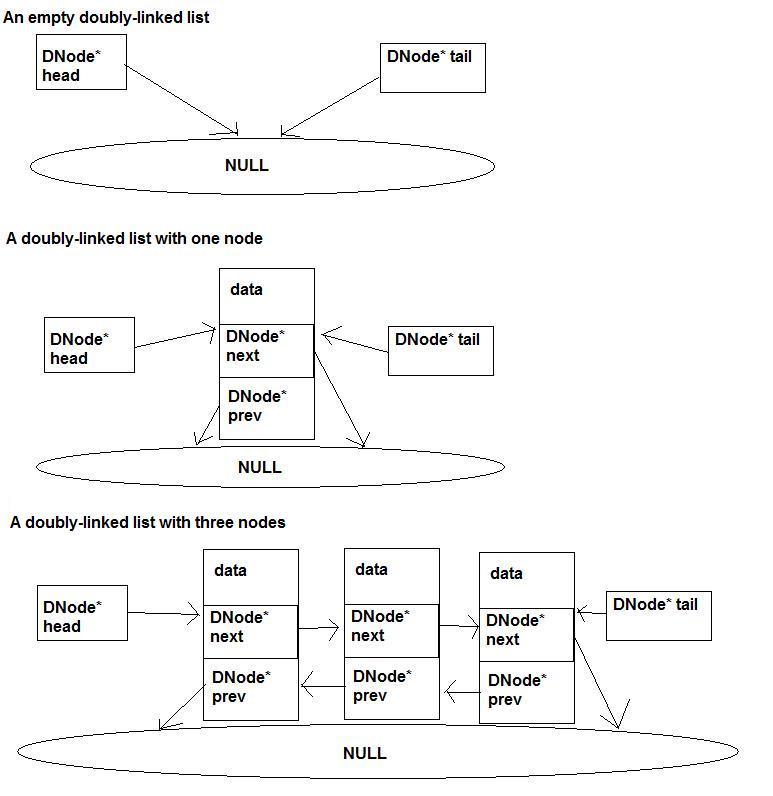
Before we continue, one thing I must point out is that the prev pointer of the node at the front of the list points to NULL and NOT head, and the next pointer of the node at the back of the list points to NULL and NOT tail. This is because head and tail are not nodes; they are pointers to nodes, so the only thing that can point to them is a Node**, which we are not using.
One thing you should also notice is that now that there is a pointer to both the first and last node in the list, we can do much more than we could before with the traverse, insert, and remove functions.
This is the DList class and its constructor:
class DList
{
public:
DNode* head;
DNode* tail;
DList();
void dTraverse();
void dBackTraverse();
bool isEmpty();
void insertFront(int x);
void insertBack(int x);
int removeFront();
int removeBack();
void insertIth(int x, int pos);
int removeIth(int pos);
~DList();
};
DList::DList()
{
head = NULL;
tail = NULL;
}
As you can see, the constructor for a doubly-linked List is pretty much the same as the constructor for a singly-linked list except now we have two nodes to initialize.
Remember when we had this function from traversing a singly-linked list from the head? (We will use the iterative version).
void LinkedList::traverse()
{
Node* search = head;
while(search != NULL)
{
cout<< search -> data << endl;
search = search -> next;
}
}
Let’s make that into a traverse function that works for doubly-linked lists!
void DList::dTraverse()
{
DNode* search = head;
while(search != NULL)
{
cout<< search -> data << endl;
search = search -> next;
}
}
As you can see, the function looks almost exactly the same as it did in a singly-linked list!
Now here’s where it gets interesting. We’re going to make this traversal go BACKWARDS! The function for that looks like THIS in a singly-linked list.
//Note: Because this code was just written to demonstrate the inefficiency of singly-linked lists in backward traversals, I did NOT test this code.
void backTraverse(Node* head)
{
int size = 0;
Node* countSize = head;
while(countSize != NULL)
{
countSize = countSize -> next;
size++;
}
for(int i = size - 1; i > 0; i++)
{
Node* toPrint = head;
for(int j = 0; j < i; j++)
toPrint = toPrint -> next;
cout<< toPrint -> data;
}
}
Oh my god. My head hurts from that traversal. And don’t even get me started on the long runtime of this function! To traverse a singly-linked list, what I have for the runtime is O(n2), which is rarely acceptable. Then there’s the fact that it takes two Node*s to traverse one list. That also takes up valuable programming time since the more times you traverse a data structure in dynamic memory, the more likely it is that you will mess up and cause a segfault that will leave you trapped in Halligan for all eternity trying to find it! Luckily, you will be spared since the projects have due dates so you can return to the outside world.
Luckily, with a doubly-linked list, the traversal is MUCH easier!
void DList::dBackTraverse()
{
DNode* search = tail;//1
while(search != NULL)
{
cout<< search -> data << endl;
search = search -> prev;//2
}
}
Feeling a little déjà vu? That’s right. What’s cool about traversing a doubly-linked list is that your function for traversing it backwards will look almost exactly like the function for traversing it forwards.
1. In the backwards traversal, you start at the tail of the list instead of the head.
2. Instead of search pointing to the next node with each iteration, search points to the previous node with each iteration.
Not only that, but with doubly-linked lists, both the forward and backward traversals take a nice O(n) runtime, which is as fast as a linked list traversal can be!
This is a diagram of a the traverse and dTraverse functions in action:

Also, the isEmpty function looks pretty much the same for singly and doubly-linked lists.
bool DList::isEmpty()
{
return (head == NULL);
} //Tail is not even used in this version of the isEmpty function since if there is at least one node in the list both head and tail point to a node.
These are the two insert functions for a doubly-linked list, both of which look pretty much the same as the front insert function for a singly-linked list.
Now here’s a cool thing about the insert and remove functions. With pointers at both ends, you can insert and remove from either end with a runtime of O(1)!
I will not include a singly-linked version of reaching the back this time, but you know that to insert or remove from the back of a singly-linked list, you need to first traverse the list to the back, and then insert or remove at the end. Since you have the traversal step, the insertion/removal of the last node can be at its very fastest O(n). However, as we know from studying linear singly-linked lists, the insert and remove functions in which we are inserting or removing from the end that has a pointer (the front end) have the fastest runtime possible, O(1). With a doubly-linked list, no matter which end we insert or remove from, we have O(1) as our runtime since both ends have pointers!
void DList::insertFront(int x)
{
DNode* add = new DNode;
add -> data = x;
if(!isEmpty())
{
head -> prev = add;//1
add -> next = head;
add -> prev = NULL;//2
head = add;
}
else
{
add -> next = NULL; //3
add -> prev = NULL;
head = add;
tail = add;
}
}
1. Since you are inserting into a doubly-linked list, if the list is not empty, then in addition to making sure that the new first node is linked to the old first node via the new node’s next, we need to make sure that the old first node’s prev is pointing to the new first node.
2. Since you are inserting from the front of the list, add -> next should point to the old first node, but since add will be the new first node, add -> prev should not point to anything but NULL.
3. This section of the function inserts add into an empty doubly-linked list, so therefore neither add -> next nor add -> prev should point to anything but NULL, but head and tail both need to be pointing to add since add is the only node there.
What do you bet that insertBack will look almost exactly the same?
void DList::insertBack(int x)
{
DNode* add = new DNode;
add -> data = x;
if(!isEmpty())
{
tail -> next = add;
add -> prev = tail;
add -> next = NULL;//1
tail = add;
}
else
{
add -> next = NULL; //2
add -> prev = NULL;
head = add;
tail = add;
}
}
1. Since you are inserting from the back of the list, add -> prev should point to the old last node, but since add will be the new last node, add -> next should not point to anything but NULL. Likewise, you need to make sure that the old last node’s next is pointing to the new last node.
2. The else section of the function is exactly the same as before. Since the else section’s code is only run if you insert into an empty list, all of the pointers still need to be set to point either to NULL or the one node in the list.
This is what the insertion looks like:

removeFront and removeBack are also very similar to the front remove of a singly-linked list.
//Invariant: removeFront is not to be used on empty lists.
int DList::removeFront()
{
DNode* temp = head;
int x = temp -> data;
if(head != tail)//1
{
head = temp -> next;//2
head -> prev = NULL;//3
}
else //4
{
head = NULL;
tail = NULL;
}
delete temp;
return x;
}
1. If head != tail, that means head and tail point to different nodes, and that means the list size is greater than one.
2. Head now points to the current second node of the list (temp points to the first node so temp -> next is the second node).
3. The prev pointer of the second node, which head is now pointing to, points to NULL, no longer connecting to the first node and thus making it so that the second node is the first node and only temp connects to the old first node. Temp is then deleted, completely removing the old first node.
4. The else statement only executes if the list’s size is 1 (if the list’s size is 0, we are violating the function’s invariant!). Since we are removing the only node in the list if this statement executes, we make head and tail both point to NULL so that we have an empty list.
As for removeBack, I’m going to leave you to think about how to write that function. Want a hint? Let’s just say that the doubly-linked property of the list means that anything you can do with one end you can do with the other the same way.
However, an important thing to notice here is that since removeBack, much like insertBack does not require any traversal like it would in a singly-linked list, both the front and back versions of insert and remove give us an awesome O(1) runtime.
Here’s a diagram of the remove function (I’m only showing you removeFront this time because I don’t want to give you too many hints on how to make removeBack. Okay okay you win. I’ll give you one more hint. Look at the insert diagram and see how insertBack corresponds to insertFront. Then think about how removeBack would correspond to removeFront in this really tall drawing.)

The doubly-linked property does provide a little bit of a challenge with the ith versions of insert and remove.
//Invariant: insertIth is never used to insert at a position greater than the size of the list.
//Note: The insertIth and removeIth functions will use indexing that starts with zero to prevent confusion with array indexing.
void DList::insertIth(int x, int pos)
{
DNode* add = new DNode;
add -> data = x;
if(pos == 0)//1
{
insertFront(x);
}
else
{
DNode* temp = head;
for(int i = 0; i < pos - 1; i++)//2
temp = temp -> next;
if(temp == tail) //3
{
insertBack(x);
}
else //4
{
add -> next = temp -> next;
add -> prev = temp;
temp -> next -> prev = add;
temp -> next = add;
}
}
}
1. Much like insertIth in a singly-linked list, if we are inserting at position 0, we just call insertFront since it can do the same insertion with a runtime of O(1) without any extra code in the insertIth function.
2. Like in the singly-linked list version of insertIth, we iterate temp so that it goes to the position right before where we want to insert.
3. Now here’s where the doubly-linked list’s version of insertIth gets interesting. Since insertBack in a doubly-linked list has a runtime of O(1), instead of adding extra code for the condition of adding at the tail, we can just call insertBack.
4. If the else statement executes, we are inserting a node somewhere in the middle of the list. To do this, we have temp pointing to the node that will be before the new node, so temp -> next currently points to the node that will be after the new node. Because of this, add -> next should be pointing to temp -> next, and add -> prev should be pointing to temp, putting the new node’s pointers in position. However, we still have to deal with temp and temp -> next. We need to make temp’s next point to the new node. We also need to make temp -> next’s prev point to the new node. With the code above, we make that happen.
insertIth at the front and back both call pre-made insert functions, so there are no surprises there. Because of this, I will just show you a diagram of insertIth at a node in the middle.

Now to see the removeIth function:
//Invariants: removeIth is never used to remove a node from a position greater than the size of the list and removeIth will never be used on an empty list.
int DList::removeIth(int pos)
{
if(pos == 0)//1
{
return removeFront();//2
}
else
{
DNode* temp = head;
for(int i = 0; i < pos; i++)//3
temp = temp -> next;
if(tail == temp)//4
{
return removeBack();//2
}
else //5
{
temp -> prev -> next = temp -> next;
temp -> next -> prev = temp -> prev;
int x = temp -> data;
delete temp;
return x;
}
}
}
1/4. Like with insertIth, if we are working with either removing at the head or tail, we can just use removeFront and removeBack.
2. Note that if we use removeFront and removeBack we still need to have a return value.
3. Unlike removeIth in a singly-linked lists, since doubly-linked lists have the doubly-linked property, we only need one temp and we can just iterate it to the position that we want to remove from.
5. If we are removing from a node in the middle of the list, we need to make it so that the node before temp’s node (temp -> prev) and the node after temp’s node (temp -> next) are linked together with their DNode*s (temp -> prev -> next and temp -> next -> prev).
Like with insertIth, since removing at the ends is covered by the removeFront and removeBack functions, I will just show a drawing for the unique case of removing a node somewhere in the middle of the list.

Finally, one more function you need to know about is the class destructor:
DList::~DList()
{
while(!isEmpty())
removeFront();
}
Note that the doubly-linked list destructor looks just like the singly-linked list destructor!
So, that wraps up linked lists for now. Next we will be learning about stacks. However, there is something I hope you noticed about the runtime of doubly-linked lists.
For the isEmpty function, both singly and doubly linked lists have a runtime of O(1)
For traversing the list, singly-linked lists have a runtime of O(n) when going forward and O(n2) when going backward, whereas doubly-linked lists have a runtime of O(n) when going either direction.
For inserting, singly-linked lists have a runtime of O(1) for inserting at the front end, O(n) for inserting at the back end, and O(n) for inserting at the ith position. Doubly-linked lists have a runtime of O(1) for inserting at either end, and a runtime of O(n) for inserting at the ith position.
For removing, singly-linked lists have a runtime of O(1) for removing from the front end, O(n) for removing from the back end, and O(n) for removing at the ith position. Doubly-linked lists have a runtime of O(1) for removing from either end, and a runtime of O(n) for removing at the ith position.
As you can see, for all functions, doubly-linked lists have a runtime that is either equal to or faster than the runtime of singly-linked lists with the same functions. Because of this, doubly-linked lists are extremely useful, however there is still a trade-off. The trade-off is that to give a linked list the doubly-linked property, it is harder to write the doubly-linked list’s functions due to having to maintain the doubly-linked property.
Next, you will be learning about stacks and queues, which can be implemented either as arrays or as an application of singly and doubly-linked lists!
No comments :
Post a Comment